alerting, prometheus, secret management, management endpoints, ui, prompt management, finetuning, batch
note
v1.57.8-stable, is currently being tested. It will be released on 2025-01-12.
New / Updated Models
- Mistral large pricing - https://github.com/BerriAI/litellm/pull/7452
- Cohere command-r7b-12-2024 pricing - https://github.com/BerriAI/litellm/pull/7553/files
- Voyage - new models, prices and context window information - https://github.com/BerriAI/litellm/pull/7472
- Anthropic - bump Bedrock claude-3-5-haiku max_output_tokens to 8192
General Proxy Improvements
- Health check support for realtime models
- Support calling Azure realtime routes via virtual keys
- Support custom tokenizer on
/utils/token_counter- useful when checking token count for self-hosted models - Request Prioritization - support on
/v1/completionendpoint as well
LLM Translation Improvements
- Deepgram STT support. Start Here
- OpenAI Moderations -
omni-moderation-latestsupport. Start Here - Azure O1 - fake streaming support. This ensures if a
stream=trueis passed, the response is streamed. Start Here - Anthropic - non-whitespace char stop sequence handling - PR
- Azure OpenAI - support entrata id username + password based auth. Start Here
- LM Studio - embedding route support. Start Here
- WatsonX - ZenAPIKeyAuth support. Start Here
Prompt Management Improvements
- Langfuse integration
- HumanLoop integration
- Support for using load balanced models
- Support for loading optional params from prompt manager
Finetuning + Batch APIs Improvements
- Improved unified endpoint support for Vertex AI finetuning - PR
- Add support for retrieving vertex api batch jobs - PR
NEW Alerting Integration
PagerDuty Alerting Integration.
Handles two types of alerts:
- High LLM API Failure Rate. Configure X fails in Y seconds to trigger an alert.
- High Number of Hanging LLM Requests. Configure X hangs in Y seconds to trigger an alert.
Prometheus Improvements
Added support for tracking latency/spend/tokens based on custom metrics. Start Here
NEW Hashicorp Secret Manager Support
Support for reading credentials + writing LLM API keys. Start Here
Management Endpoints / UI Improvements
- Create and view organizations + assign org admins on the Proxy UI
- Support deleting keys by key_alias
- Allow assigning teams to org on UI
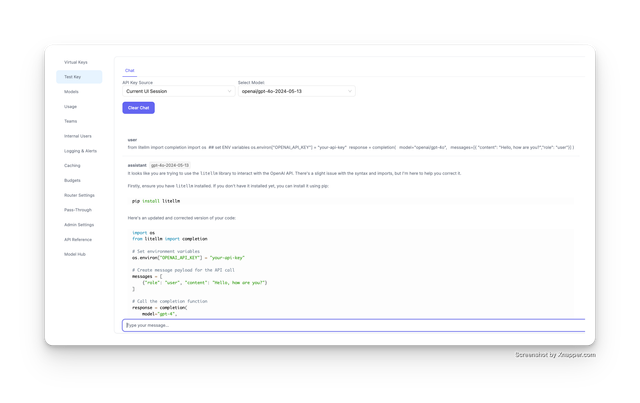
- Disable using ui session token for 'test key' pane
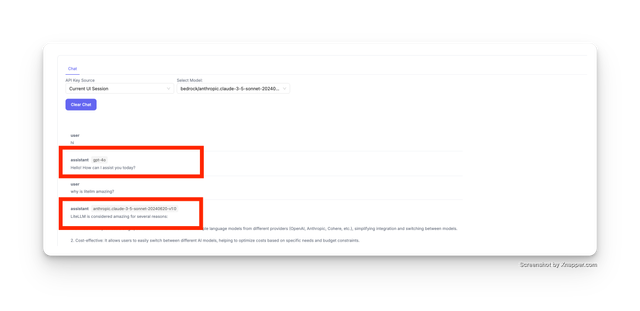
- Show model used in 'test key' pane
- Support markdown output in 'test key' pane
Helm Improvements
- Prevent istio injection for db migrations cron job
- allow using migrationJob.enabled variable within job
Logging Improvements
- braintrust logging: respect project_id, add more metrics - https://github.com/BerriAI/litellm/pull/7613
- Athina - support base url -
ATHINA_BASE_URL - Lunary - Allow passing custom parent run id to LLM Calls
Git Diff
This is the diff between v1.56.3-stable and v1.57.8-stable.
Use this to see the changes in the codebase.